Как использовать Slither для поиска ошибок в умных контрактах
Как использовать Slither
Цель этого руководства — показать, как использовать Slither для автоматического поиска ошибок в умных контрактах.
- Установка
- Использование командной строки
- Введение в статический анализ: краткое введение в статический анализ
- API: описание API Python
Установка
Slither требует Python >= 3.6. Его можно установить через pip или с помощью Docker.
Slither через pip:
pip3 install --user slither-analyzerSlither через docker:
docker pull trailofbits/eth-security-toolboxdocker run -it -v "$PWD":/home/trufflecon trailofbits/eth-security-toolboxПоследняя команда запускает eth-security-toolbox в контейнере Docker, который имеет доступ к вашему текущему каталогу. Вы можете изменять файлы со своего хоста и запускать инструменты для работы с этими файлами из контейнера Docker_
Внутри контейнера Docker выполните:
solc-select 0.5.11cd /home/trufflecon/Запуск скрипта
Чтобы запустить скрипт Python с помощью Python 3:
python3 script.pyКомандная строка
Командная строка в сравнении с пользовательскими скриптами. Slither поставляется с набором предопределенных детекторов, которые находят много распространенных ошибок. Вызов Slither из командной строки запустит все детекторы, при этом не требуются глубокие знания статического анализа:
slither project_pathsВ дополнение к детекторам Slither имеет возможности анализа кода с помощью своих принтеров (opens in a new tab) и инструментов (opens in a new tab).
Используйте crytic.io (opens in a new tab), чтобы получить доступ к приватным детекторам и интеграции с GitHub.
Статический анализ
Возможности и дизайн фреймворка статического анализа Slither были описаны в постах в блоге (1 (opens in a new tab), 2 (opens in a new tab)) и научной статье (opens in a new tab).
Статический анализ существует в разных вариантах. Вы, скорее всего, понимаете, что компиляторы, такие как clang (opens in a new tab) и gcc (opens in a new tab), зависят от этих исследовательских техник, но они также лежат в основе (Infer (opens in a new tab), CodeClimate (opens in a new tab), FindBugs (opens in a new tab) и инструментов, основанных на формальных методах, таких как Frama-C (opens in a new tab) и Polyspace (opens in a new tab)).
Мы не будем здесь исчерпывающе рассматривать техники статического анализа и исследования. Вместо этого мы сосредоточимся на том, что необходимо для понимания работы Slither, чтобы вы могли более эффективно использовать его для поиска ошибок и понимания кода.
Представление кода
В отличие от динамического анализа, который рассматривает один путь выполнения, статический анализ рассматривает все пути одновременно. Для этого он использует другое представление кода. Два наиболее распространенных — это абстрактное синтаксическое дерево (AST) и граф потока управления (CFG).
Абстрактные синтаксические деревья (AST)
AST используются каждый раз, когда компилятор анализирует код. Это, вероятно, самая основная структура, на которой может выполняться статический анализ.
Вкратце, AST — это структурированное дерево, где, как правило, каждый лист содержит переменную или константу, а внутренние узлы являются операндами или операциями управления потоком. Рассмотрим следующий код:
1function safeAdd(uint a, uint b) pure internal returns(uint){2 if(a + b <= a){3 revert();4 }5 return a + b;6}Соответствующее дерево AST показано ниже:
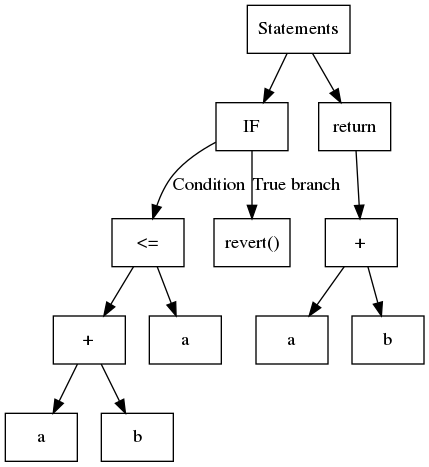
Slither использует AST, экспортируемый компилятором solc.
Хотя AST легко построить, он представляет собой вложенную структуру. Иногда его анализировать не так просто. Например, чтобы определить операции, используемые в выражении a + b <= a, вы должны сначала проанализировать <= а затем +. Распространенным подходом является использование так называемого шаблона «посетитель», который рекурсивно обходит дерево. Slither содержит универсальный «посетитель» в ExpressionVisitor (opens in a new tab).
Следующий код использует ExpressionVisitor для определения, содержит ли выражение операцию сложения:
1from slither.visitors.expression.expression import ExpressionVisitor2from slither.core.expressions.binary_operation import BinaryOperationType34class HasAddition(ExpressionVisitor):56 def result(self):7 return self._result89 def _post_binary_operation(self, expression):10 if expression.type == BinaryOperationType.ADDITION:11 self._result = True1213visitor = HasAddition(expression) # expression — это проверяемое выражение14print(f'Выражение {expression} содержит сложение: {visitor.result()}')Показать всеГраф потока управления (CFG)
Второе по распространенности представление кода — это граф потока управления (CFG). Как следует из названия, это представление на основе графа, которое показывает все пути выполнения. Каждый узел содержит одну или несколько инструкций. Ребра в графе представляют операции управления потоком (if/then/else, цикл и т. д.). CFG для нашего предыдущего примера следующий:
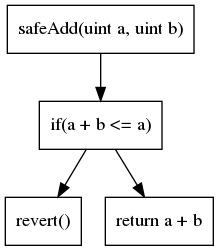
CFG — это представление, на основе которого построено большинство видов анализа.
Существует много других представлений кода. Каждое представление имеет свои преимущества и недостатки в зависимости от анализа, который вы хотите выполнить.
Анализ
Простейший тип анализа, который можно выполнить с помощью Slither, — это синтаксический анализ.
Синтаксический анализ
Slither может перемещаться по различным компонентам кода и их представлениям, чтобы находить несоответствия и недостатки с помощью подхода, подобного сопоставлению с образцом.
Например, следующие детекторы ищут проблемы, связанные с синтаксисом:
-
Сокрытие переменной состояния (opens in a new tab): перебирает все переменные состояния и проверяет, не скрывает ли какая-либо из них переменную из унаследованного контракта (state.py#L51-L62 (opens in a new tab))
-
Неправильный интерфейс ERC20 (opens in a new tab): ищет неправильные сигнатуры функций ERC20 (incorrect_erc20_interface.py#L34-L55 (opens in a new tab))
Семантический анализ
В отличие от синтаксического анализа, семантический анализ идет глубже и анализирует «смысл» кода. Эта категория включает несколько обширных типов анализа. Они позволяют получать более мощные и полезные результаты, но и писать их сложнее.
Семантический анализ используется для обнаружения наиболее сложных уязвимостей.
Анализ зависимостей данных
Говорят, что переменная variable_a зависит по данным от variable_b, если существует путь, в котором на значение variable_a влияет variable_b.
В следующем коде variable_a зависит от variable_b:
1// ...2variable_a = variable_b + 1;Slither поставляется со встроенными возможностями анализа зависимостей по данным (opens in a new tab) благодаря своему промежуточному представлению (обсуждается в одном из следующих разделов).
Пример использования зависимостей по данным можно найти в детекторе опасного строгого равенства (opens in a new tab). Здесь Slither будет искать сравнение на строгое равенство с опасным значением (incorrect_strict_equality.py#L86-L87 (opens in a new tab)) и сообщит пользователю, что следует использовать >= или <= вместо ==, чтобы злоумышленник не смог заблокировать контракт. Помимо прочего, детектор будет считать опасным возвращаемое значение вызова balanceOf(address) (incorrect_strict_equality.py#L63-L64 (opens in a new tab)) и будет использовать механизм зависимостей по данным для отслеживания его использования.
Вычисление с неподвижной точкой
Если ваш анализ перемещается по CFG и следует по ребрам, вы, скорее всего, увидите уже посещенные узлы. Например, если цикл представлен так, как показано ниже:
1for(uint i; i < range; ++){2 variable_a += 13}Вашему анализу нужно будет знать, когда остановиться. Здесь есть две основные стратегии: (1) выполнить итерацию для каждого узла конечное число раз, (2) вычислить так называемую неподвижную точку. Неподвижная точка по сути означает, что анализ этого узла больше не дает никакой значимой информации.
Пример использования неподвижной точки можно найти в детекторах повторного входа: Slither исследует узлы и ищет внешние вызовы, запись в хранилище и чтение из него. Как только будет достигнута неподвижная точка (reentrancy.py#L125-L131 (opens in a new tab)), он останавливает исследование и анализирует результаты, чтобы определить, присутствует ли возможность повторного входа, с помощью различных шаблонов повторного входа (reentrancy_benign.py (opens in a new tab), reentrancy_read_before_write.py (opens in a new tab), reentrancy_eth.py (opens in a new tab)).
Написание анализов с использованием эффективного вычисления неподвижной точки требует хорошего понимания того, как анализ распространяет информацию.
Промежуточное представление
Промежуточное представление (IR) — это язык, который должен быть более удобен для статического анализа, чем исходный. Slither переводит Solidity в собственное промежуточное представление: SlithIR (opens in a new tab).
Понимание SlithIR не является обязательным, если вы хотите писать только базовые проверки. Однако это пригодится, если вы планируете писать сложные семантические анализы. Принтеры SlithIR (opens in a new tab) и SSA (opens in a new tab) помогут вам понять, как переводится код.
Основы API
У Slither есть API, который позволяет исследовать основные атрибуты контракта и его функций.
Чтобы загрузить кодовую базу:
1from slither import Slither2slither = Slither('/path/to/project')3Исследование контрактов и функций
Объект Slither имеет:
contracts (list(Contract)): список контрактовcontracts_derived (list(Contract)): список контрактов, не унаследованных от другого контракта (подмножество контрактов)get_contract_from_name (str): возвращает контракт по его имени
Объект Contract имеет:
name (str): имя контрактаfunctions (list(Function)): список функцийmodifiers (list(Modifier)): список модификаторовall_functions_called (list(Function/Modifier)): список всех внутренних функций, достижимых из контрактаinheritance (list(Contract)): список унаследованных контрактовget_function_from_signature (str): возвращает функцию по ее сигнатуреget_modifier_from_signature (str): возвращает модификатор по его сигнатуреget_state_variable_from_name (str): возвращает переменную состояния по ее имени
Объект Function или Modifier имеет:
name (str): имя функцииcontract (contract): контракт, в котором объявлена функцияnodes (list(Node)): список узлов, составляющих CFG функции/модификатораentry_point (Node): точка входа CFGvariables_read (list(Variable)): список прочитанных переменныхvariables_written (list(Variable)): список записанных переменныхstate_variables_read (list(StateVariable)): список прочитанных переменных состояния (подмножествоvariables_read)state_variables_written (list(StateVariable)): список записанных переменных состояния (подмножествоvariables_written)
Последнее обновление страницы: 3 февраля 2025 г.


